
QitChain: Distributed Search Engine in the Web3.0 Era
Web 3.0: Transforming users’ content output into digital assets
As we all know, from the perspective of historical experience, the development of science and technology has always been characterized by “concept first” — that is, the concept of new technology comes first, and then the application will follow. Looking back at the time period from the end of 2021 to the beginning of 2022, the most popular technology concept, in addition to the “metaverse”, another rising star that has attracted a lot of attention is “Web 3.0”.
Before introducing the concept of “Web 3.0”, it is necessary to review the concepts of “Web 1.0” and “Web 2.0”. In the earliest world of the World Wide Web, content platforms took on all the elements of information content — namely, content creation, ownership, review rights, and revenue. In this process, users can only receive information passively, so “Web 1.0” is also called “static Internet”.
The concept of “Web 2.0” emerged with the rise of social networks and e-commerce platforms. In this scenario, the platform is mainly responsible for the technical construction of infrastructure, while the creation of content is transferred to users. However, because the content needs to be carried by the infrastructure, the platform obtains the ownership and review rights of the content created by the user, and at the same time participates in the value share generated by the content, and thus enjoys the pricing power of the share.
As an emerging technology, blockchain, with its unique characteristics of “distribution” and “non-tampering”, makes it possible for creators to hold their own ownership in their own hands by uploading content to the chain. Bargaining power for this creative content. Under this system, the created digital content has thus become a digital asset. For example, NFT, which was very popular before, is one of the landing applications of the above-mentioned content assetization. And this system that content creators can enjoy ownership and distribute value based on protocols is the most important feature of “Web 3.0”.
Now let’s go back to the current Web 2.0 era scenario. Suppose someone searches for the term “men’s coat” in a centralized search engine, then, based on big data technology, the record will be tracked. And when he browses e-commerce websites later, it will be easier to receive product pushes for men’s coats. On the one hand, this process allows the centralized search engine to obtain huge profits, and on the other hand, it completely exposes the privacy of every user. In order to make value return to users and solve the problem of privacy exposure, the distributed search engine represented by QitChain came into being, which can not only protect user search records as privacy, but also provide users with a transparent experience of non-PPC ranking.
The dilemma faced by distributed search
Before starting to discuss QitChain systematically, it is necessary for us to review the “impossible triangle” in the context of blockchain, namely distributed, high security and high performance. QitChain is essentially a stand-out distributed search engine, and its excellence must be a reasonable trade-off between high security and high performance. Therefore, we can gradually reveal the excellence of the project by discussing the technical architecture, consensus and ecological environment of QitChain.
In the blockchain projects represented by the BTC public chain, when a user initiates a search request, the search tool will traverse all blocks to find the transaction information specified by the user. There is no doubt that full node search is safe, then its inefficiency is inevitable. With the continuous development of technology and application scenarios, the search method of traversing the entire public chain has begun to highlight its defects. These defects mainly include the following points:
The first is the lack of semantic relevance search capabilities. The current mainstream method of storing data in blocks is still to store it in key-value databases or system files. Therefore, although the transaction data itself is structured, it is constrained by the non-relational nature of key-value databases and the isolation of system files. which makes it difficult to meet the requirements of using traditional methods to perform joint table query or multi-condition filtering on multiple data tables.
Second, the data processing capability of full-node search is relatively limited. In existing mainstream systems, block data is often stored in key-value databases or file systems, both of which can only support relatively simple queries. Although the transaction data in the blockchain is currently structured, the current system does not support relational query of data directly on the chain. A current compromise is to import the on-chain data into an offline relational database and then search it. But there is no doubt that data migration, replication, and storage will incur additional system costs.
Finally, on-chain and off-chain data integration is a very complex task. In current data storage solutions, large amounts of data are stored in off-chain relational databases. This centralized off-chain storage undoubtedly increases the security risk of the entire system. In addition, these data are also independently stored in the on-chain and off-chain databases at the same time. This separation will also lead to complex on-chain Integration with off-chain data makes it impossible for users to use smart contracts to access offline data. Another flaw is that the process of importing the on-chain database into the off-chain will inevitably increase the maintenance cost of the database.
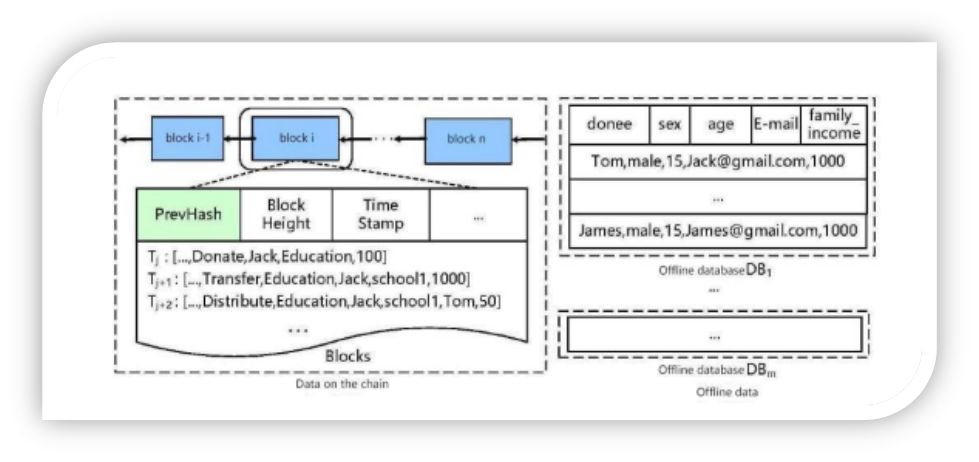
Considering the rigid requirements for search capability, efficiency and cost in actual operation, the full-node search that traverses the entire block has already experienced some decline, and is replaced by the light-node search — the so-called light-node refers to Nodes that only store headers and not all transaction data. The light node search can quickly verify the existence of a transaction through the Merkle proof method while saving the block header of the main chain. It can be seen that in the balance between security and performance, light node search chooses performance as its focus.
Infrastructure of QitChain
Considering that in the not-too-distant Web 3.0 era, distributed engines will inevitably be widely opened to the public, the balance between security and search efficiency will inevitably be tilted toward the latter. As one of the important members of the distributed track, QitChain is particularly important for the blockchain industry to have a brief understanding of its technical architecture. Therefore, the following will briefly introduce the basic technical architecture of QitChain for readers’ understanding and reference.
The following diagram shows the infrastructure of QitChain. As shown in the figure below, QitChain’s infrastructure is mainly divided into four parts, namely Certificate Authority (CA), full node, light node and off-chain database. The organic combination of these four parts allows each participant to participate in the maintenance of the node, thereby forming a trusted network alliance chain:

In the alliance chain, four parts have different responsibilities, so as to jointly form a set of light, efficient and relatively complete distributed search engine, and the responsibilities of these four parts in the structure are:
Certificate Authority (CA):
The certificate authority is responsible for issuing and managing digital certificates, as well as verifying the validity of the public key system. The certificate authority is generally held by a trusted third party to ensure its impartiality and transparency.
Full Nodes:
In the context of QitChain, full nodes refer to those nodes that participate in consensus and store complete data. Due to the huge amount of data stored in full nodes, they have strict requirements on storage, computing and network resources; and similarly, users who are responsible for maintaining such full nodes also need to pay considerable maintenance costs.
Light Nodes:
Individual users usually only need to maintain light nodes in QitChain, and do not need to bear the high maintenance costs like users of full nodes. The request that needs to use the global query will be handed over to the full node for processing.
Off-Chain Database:
In the QitChain network, all big data and private data are stored in the off-chain database, which can avoid the leakage of private data and reduce the network overhead of the entire system. By adjusting configuration files, QitChain can connect to different off-chain databases. When users query data, they can query an off-chain database individually, or they can perform joint query through QitChain. In addition, QitChain is as user-friendly as possible in terms of technical barriers. For example, its ability to fully support the SQL language greatly reduces the technical barriers for users.
From the perspective of the comprehensive architecture, the entire QitChain network is actually a relatively accurate “tailor-made” architecture. By distinguishing between full nodes and light nodes, individual users and institutional users are distinguished; Improve the efficiency of the query, so as to achieve a relatively appropriate distribution ratio between high security and high performance, thereby realizing the landing application of distributed search.
Since there are both full nodes and light nodes in the QitChain network, there will inevitably be a big difference in the computing power of their maintainers, institutions and individual users, and this difference cannot but cause a concern. Previously, whether PoW or PoS consensus was adopted, the computing power and technical differences between individual users and institutions would trigger the Matthew effect on resources, making the strong stronger and the weak weaker, eventually forming a centralized monopoly. And QitChain is trying to solve this problem by adopting a new consensus — CPoC. In subsequent articles, we will introduce the specific content of CPoC and discuss how this consensus can inhibit the Matthew effect and centralization of digital assets.
In general, at the beginning of its design, QitChain has carried out various corresponding solutions to the difficulties encountered by distributed search engines, and these designs have also attracted considerable attention on the search engine track. However, in the blockchain industry, the highlight of a project is not the winning point, and widespread attention is not the same as immediate success. Therefore, how QitChain’s design aimed at the pain points of the current distributed search engine can establish advantages for it to build a complete and prosperous ecology is still a matter to be proved by time. But if you want to sum it up in one word, the QitChain project itself is worth waiting and seeing.
Conclusion
As the era of Web 3.0 approaches, the blockchain industry has also begun to subdivide the track. And the leaders of various sub-tracks have also begun to sprout up like mushrooms after a spring rain. It is foreseeable that the efficient and relatively transparent QitChain Network, with its unique CPoC consensus mechanism (which will be mentioned in detail in later articles) and a relatively reasonable architecture, will most likely become a leader in the distributed search engine race. leading contender.
related article: Distributed Search Engine || Economic Model of Distributed Search Engine QTC